






















Hurtownia danych czy Data Lakehouse? Architektura, która realnie wspiera rozwój biznesu
⏱️ Czas czytania: ok. 8-10 minut
Większość dynamicznie rozwijających się przedsiębiorstw dociera w pewnym momencie do ściany, w której tradycyjne arkusze kalkulacyjne przestają wystarczać. Wyobraź sobie spotkanie zarządu, na którym menedżerowie próbują podjąć kluczową decyzję budżetową. Każdy z nich wyciąga z kieszeni „swojego” Excela i prezentuje zupełnie inne liczby. Zamiast merytorycznej dyskusji o strategii, spotkanie zamienia się w spór o to, czyj raport zawiera prawdziwe dane.
Brzmi znajomo? To klasyczny efekt rozproszenia informacji w dziesiątkach systemów ERP, CRM czy platformach marketingowych. Rozwiązaniem tego chaosu jest nowoczesna platforma danych. Pojawia się jednak fundamentalne pytanie: Jaka architektura? Klasyczna hurtownia danych (DWH) czy nowoczesny Data Lakehouse. Które rozwiązanie realnie napędzi rozwój Twojego biznesu?
Nowoczesna hurtownia danych kontra Data Lakehouse - co wybrać?
Przez lata standardem w biznesie była tradycyjna hurtownia danych, czyli scentralizowana baza danych przeznaczona do analizowania ustrukturyzowanych danych transakcyjnych; dziś nowoczesne hurtownie danych to bardziej rozbudowany cyfrowy system przechowywania danych niż klasyczna baza, a starsze rozwiązania coraz częściej potrzebują modernizacji w celu uelastycznienia. Taka nowoczesna hurtownia jako cyfrowy system nie jest przeznaczona wyłącznie do prostego składowania, bo obsługuje zarówno dane ustrukturyzowane, jak i nieustrukturyzowane, wspierając analitykę i raportowanie w skali całej organizacji. Z kolei Data Lakes są rozwiązaniem, w które przechowuje dane surowe, nieustrukturyzowane i półustrukturyzowane w różnych formatach.
Dzisiaj nowoczesna hurtownia danych to bardziej rozbudowany cyfrowy system przechowywania danych niż klasyczna baza, a tradycyjne systemy coraz częściej ustępują rozwiązaniom bardziej elastycznym. Dzisiejsza rewolucja technologiczna, napędzana przez chmurę obliczeniową i sztuczną inteligencję (AI), zatarła te granice, rodząc koncepcję Data Lakehouse. Łączy ona najlepsze cechy obu światów: elastyczność i niski koszt przechowywania surowych plików (jak w data lake) z pełną strukturą, szybkością zapytań SQL oraz bezkompromisowymi gwarancjami transakcji ACID (atomowości, spójności, izolacji i trwałości). Ułatwia to pracę z różnymi formami informacji i porządkuje je w jeden spójny ekosystem, bez jakiejkolwiek utraty elastyczności operacyjnej.
Dla liderów biznesowych wybór ten sprowadza się do odpowiedzi na pytanie: jakich danych potrzebujemy i jak zamierzamy je konsumować? Jeśli Twoja firma bazuje głównie na raportach finansowych i tabelach z systemów ERP, nowoczesna, chmurowa hurtownia danych (np. Google BigQuery) w pełni zabezpieczy Twoje potrzeby i pozwoli bezpiecznie wykorzystywać Twoje dane. Jeśli jednak planujesz wdrażać zaawansowaną analitykę predykcyjną, analizować zachowania klientów w czasie rzeczywistym lub karmić modele sztucznej inteligencji danymi nieustrukturyzowanymi (np. dokumentami PDF czy logami), naturalnym kierunkiem staje się Data Lakehouse, bo pozwala przyjmować duże ilości danych w czasie rzeczywistym bez wcześniejszego modelowania schematu.

Projektowanie architektury, czyli jak zbudować bezpieczny i skalowalny fundament
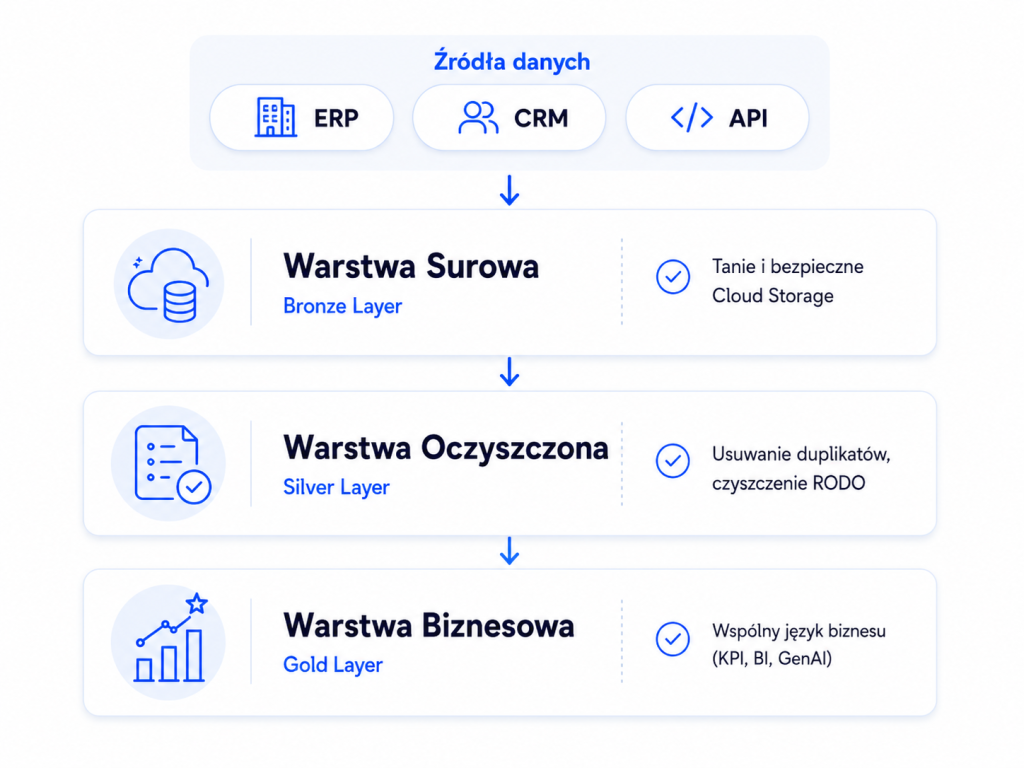
Niezależnie od wybranego modelu, skuteczna budowa hurtowni danych lub platformy typu Lakehouse nie może być chaotycznym procesem technologicznym. Architektura musi odzwierciedlać cele biznesowe. Dobrze zaprojektowane data architectures obejmują lakehouse, hurtownię i pozostałe komponenty potrzebne do analityki. Kluczową rolę odgrywa tu integracji danych z różnych źródeł w spójny widok potrzebny do analizy biznesowej; dobrze zaprojektowana integracja pozwala też na szybsze przetwarzanie zapytań oraz lepszą jakość danych, co jest niezbędne do podejmowania trafnych decyzji w organizacji. W praktyce dane przepływają przez procesy ETL, które obejmują ekstrakcję, transformację i ładowania danych do hurtowni. W Alterdata realizujemy to poprzez ustrukturyzowany proces architektoniczny, gdzie architektura hurtowni porządkuje układ warstw wspierających analizę i decyzje biznesowe, podzielony na wyraźne warstwy:
1. Warstwa surowa (Bronze Layer / Ingestion)
Tutaj trafiają nienaruszone dane bezpośrednio ze źródeł (systemy POS, dane z aplikacji mobilnych, bazy transakcyjne), a także z aplikacji biznesowych i mediów społecznościowych, z danymi napływającymi z różnych kanałów, co dobrze wpisuje się w scenariusze big data. Gromadzenie ich w tanich przestrzeniach dyskowych (np. Cloud Storage) gwarantuje, że nigdy nie stracimy historycznego kontekstu, bo w tej warstwie mogą być przechowywane raw data w oryginalnym formacie, wraz z możliwością przyjmowania data in różnych formach i na różnych etapach obróbki, i w dużych ilościach.
2. Warstwa oczyszczona (Silver Layer / Storage & Processing)
Surowy chaos zamieniamy w uporządkowany zbiór, przygotowany do dalszego zasilania różnych magazynów analitycznych i innych magazynów. Na tym etapie dane są ujednolicane, co jest kluczowe dla zarządzania jakością danych i przygotowania do analizy danych oraz zapewnia spójność, jakiej wymaga zaprojektowana hurtownia danych, usuwane są duplikaty, błędy oraz informacje wrażliwe (zgodnie z wymogami RODO). Tutaj standaryzowane są też dane pochodzące z systemów operacyjnych i innych źródeł przed dalszym wykorzystaniem.
3. Warstwa biznesowa (Gold Layer / Consumption)
To docelowy model danych gotowy do natychmiastowego użycia, przygotowany do raportowania i eksploracji danych przez użytkowników biznesowych. To górna warstwa architektury, w której użytkownik końcowy konsumuje dane. To tutaj definiowane są spójne, unikalne wskaźniki KPI dla całej organizacji, co ułatwia użytkownikom samodzielne tworzenie raportów bez stałego angażowania działu IT. Dane zasilają dashboardy BI (Looker, Tableau), systemy raportowe oraz modele uczenia maszynowego (ML), które mogą korzystać z danych historycznych do tworzenia raportów i budowy prognoz sugerujących optymalne działania.
Ważna lekcja architektoniczna: Małe, pochopne decyzje techniczne na początku projektu rodzą gigantyczne koszty w przyszłości. Pisanie prostych, "partyzanckich" skryptów bez myślenia o skali sprawia, że potok danych, który na początku przetwarza się w 15 minut, po roku puchnie do 4 godzin i paraliżuje pracę organizacji. Dlatego od pierwszego dnia projektujemy rozwiązania w taki sposób, aby wszystkie przepływy danych były gotowe na skalowanie horyzontalne. Budujemy architekturę modularną, która pozwala rozpraszać procesy przetwarzania na wiele niezależnych zasobów obliczeniowych, co umożliwia bezproblemowe i niemal nieograniczone zwiększanie wydajności wraz z napływem nowych danych. Dbamy przy tym o optymalizację samych struktur, separując moc obliczeniową od przechowywania danych (storage) oraz stosując precyzyjne partycjonowanie i klastrowanie tabel. Dzięki temu system rośnie płynnie wraz z biznesem, a koszty chmurowe nie wymykają się spod kontroli.
Biznesowe korzyści z wdrożenia Data Lakehouse i nowoczesnego DWH dla analizy danych
Dlaczego warto zainwestować czas i budżet w zaawansowane fundamenty danych? Ponieważ sprawnie przeprowadzona budowa hurtowni danych lub platformy Lakehouse, umożliwiają wydobywanie cennych informacji biznesowych wspierających podejmowanie decyzji, przekłada się bezpośrednio na mierzalne zyski finansowe i operacyjne podnoszące rentowność przedsiębiorstwa:
- Likwidacja silosów informacyjnych: Wszystkie departamenty od finansów przez marketing po logistykę zaczynają posługiwać się jedną wersją prawdy, co pomaga eliminować data silos i budować single source of truth dla całej organizacji.
- Przejście od reaktywnej analizy do predykcji przyszłości: Tradycyjne podejście opiera się na długich procesach wsadowych (batchach), gdzie suche dane historyczne analizuje się raz na tydzień lub miesiąc, reagując na fakty już dokonane. Nowoczesna platforma pozwala wejść na wyższy poziom dojrzałości danych. Umożliwia nie tylko analitykę w czasie rzeczywistym, ale przede wszystkim otwiera drzwi do zaawansowanej analityki proaktywnej. Dzięki modelom uczenia maszynowego (ML) i sztucznej inteligencji, organizacja zyskuje zdolność do tworzenia predykcji, czyli np. prognozowania zachowań klientów, trendów rynkowych czy optymalizacji procesów z wyprzedzeniem. Dla firm silnie zorientowanych na dane to właśnie te scenariusze prognostyczne stanowią docelowy punkt budowania przewagi konkurencyjnej.
- Skrócenie Time-to-Value: Elastyczna i skalowalna platforma w chmurze pozwala biznesowi wdrażać nowe raporty i testować hipotezy w zaledwie kilka godzin, a nie tygodni. Co ważne, przy odpowiednim zaprojektowaniu systemu opartego na analizie realnych potrzeb organizacji względem technologii. Nowoczesna platforma pozwala zoptymalizować budżet IT i płacić wyłącznie za faktycznie zużyte zasoby (pay-as-you-go), zamiast utrzymywać kosztowną, niewykorzystaną infrastrukturę.
- Optymalizacja kosztów operacyjnych: Lepsza widoczność łańcucha dostaw czy precyzyjne wykrywanie strat energii (jak w przypadku naszych wdrożeń w sektorze utilities) przynoszą natychmiastowe oszczędności liczone w milionach złotych.
Rola inżynierii danych i narzędzi automatyzacji (Dataform, dbt)
Nawet najlepszy projekt architektury nie przetrwa, jeśli pod spodem zabraknie rygorystycznych standardów inżynieryjnych. Przeprowadzanie transformacji danych bezpośrednio w bazie za pomocą nieskoordynowanych zapytań to prosta droga do powielania błędów. typowa hurtownia opiera się przecież na powtarzalnych procesach ETL i jasno zdefiniowanej architekturze.
Współczesna inżynieria danych opiera się na narzędziach takich jak Dataform czy dbt, które wprowadzają standardy znane z inżynierii oprogramowania wprost do świata analiz i wspierają współpracę, jakiej potrzebują zespoły IT, analitycy oraz inżynierowie danych:
- Śledzenie pochodzenia danych (Data Lineage): Wizualna mapa zależności pozwala prześledzić pełną ścieżkę każdego pola, od końcowego klocka w raporcie aż do surowego pliku źródłowego. Taka widoczność wspiera data management i lepsze zarządzanie przepływem danych w całej platformie. To buduje bezcenne zaufanie biznesu do prezentowanych liczb.
- Kontrola wersji i historia zmian: Każda zmiana w kodzie SQL przechodzi przez procedurę peer-review. Dokładnie wiemy, kto, kiedy i dlaczego zmodyfikował logikę wyliczania marży.
- Automatyczne testy i asercje: Platforma sama weryfikuje jakość danych przed i po wykonaniu obliczeń. Jeśli w krytycznej tabeli pojawią się puste wartości (nulle) lub anomalie kwotowe, system natychmiast alarmuje zespół, zanim błędne dane trafią na ekrany zarządu.

Gotowość na AI – Dlaczego fundamenty danych decydują o sukcesie sztucznej inteligencji?
Obecnie każdy manager chce wdrożyć w swojej organizacji systemy sztucznej inteligencji, generatywnych asystentów czy autonomicznych agentów AI. Jednak brutalna prawda brzmi: nie ma skutecznego AI bez uporządkowanych danych. W praktyce lakehouse wspiera też projekty data science i uczenie maszynowe na jednej, wspólnej platformie danych.
Wdrażanie zaawansowanych chatbotów (np. w architekturze RAG), które mają analizować wewnętrzne procedury czy dokumenty techniczne, zakończy się porażką, jeśli te same produkty będą opisane w sprzeczny sposób w różnych plikach. Dochodzi do tego potrzeba pracy na danych z wielu źródeł i w różnych formatach. Sztuczna inteligencja nakarmiona chaosem wygeneruje wyłącznie chaotyczne halucynacje.
Prawidłowo zbudowana platforma Data Lakehouse stanowi bezpieczną, odizolowaną przestrzeń, w której data lake jest elastyczną warstwą przechowywania danych, a całość wspiera również zaawansowane analizy modeli. Modele językowe (takie jak Google Gemini w Vertex AI) operują wyłącznie na sprawdzonym, zweryfikowanym kontekście biznesowym. Twoje dane firmowe nie opuszczają organizacji, nie służą do trenowania publicznych modeli, a agenty AI zwracają precyzyjne odpowiedzi poparte konkretnymi cytatami i linkami źródłowymi. Takie podejście daje zespołom umiejętności do bezpiecznego wykorzystania danych firmowych bez ich kopiowania między systemami.
Podsumowanie
Wybór między hurtownią danych a strukturą Data Lakehouse nie powinien być podyktowany modą technologiczną, lecz dojrzałością i realnymi potrzebami operacyjnymi Twojej firmy. Stabilna, modularna architektura to inwestycja, która uwalnia organizację od plemiennej wiedzy ukrytej w głowach pojedynczych specjalistów i tworzy fundament pod bezpieczne innowacje AI.
Chcesz przekształcić rozproszony chaos informacyjny w jedno, niezawodne źródło prawdy dla swojej firmy? Pragniesz przygotować swoje procesy operacyjne na wdrożenie zaawansowanych narzędzi sztucznej inteligencji?
Napisz do nas i porozmawiaj z architektem Alterdata - przeanalizujemy Twoją obecną strukturę systemową i wspólnie zaprojektujemy platformę danych dopasowaną do dynamiki rozwoju Twojego biznesu.