




























Modernizacja
Hurtowni Danych
Przygotuj swoją hurtownię danych na AI. Modernizujemy architekturę danych, aby zapewnić skalowalność, szybkość i jakość niezbędną do wdrażania zaawansowanej analityki i Generative AI.
Porozmawiajmy
Zaufali nam:











Dlaczego tradycyjna hurtownia danych
blokuje wdrożenie AI?
Wiele organizacji nie może przejść do fazy produkcyjnego AI, ponieważ ich obecna architektura danych opiera się na przestarzałych systemach typu legacy. Tradycyjne hurtownie danych nie zostały zaprojektowane z myślą o szybkości i skali, jakiej wymagają nowoczesne modele LLM, co tworzy wąskie gardło w Twoim rozwoju.

Rozproszone silosy danych
Uwięzienie danych w odseparowanych systemach uniemożliwia modelom AI uzyskanie pełnego kontekstu biznesowego niezbędnego do trafnego wnioskowania.
Wysokie koszty utrzymania
Nakłady na przestarzałą infrastrukturę on-premise marnują budżet, który powinien wspierać innowacje i rozwój Twoich projektów AI.
Zbyt rzadkie odświeżanie danych
Wydajność starszych systemów paraliżuje częstsze aktualizacje. Nawet jeśli dany proces biznesowy wymaga szybszego dostępu do informacji, przestarzała infrastruktura tworzy wąskie gardło i sztucznie opóźnia działanie algorytmów AI.
Niska wiarygodność informacji
Brak automatycznych procesów czyszczenia danych prowadzi bezpośrednio do halucynacji agentów AI i błędnych wyników analitycznych.
Brak biznesowego kontekstu (Warstwy Semantycznej)
Starsze systemy nie pozwalają na zbudowanie jednej, centralnej mapy pojęć biznesowych. W efekcie algorytmy i agenci AI „gubią się” w strukturach tabel, nie rozumiejąc prawdziwego znaczenia danych, którymi dysponuje firma.

Twoja Hurtownia danych nie może być dłużej barierą
Skontaktuj sięFundamenty nowoczesnej architektury pod AI
Przejście do Chmury (Cloud-Native)
Przejście do Chmury (Cloud-Native)
- Migracja na platformy takie jak BigQuery, Snowflake lub Databricks zapewnia natywną optymalizację pod zaawansowane algorytmy ML i AI. Architektura serverless gwarantuje błyskawiczne skalowanie zasobów oraz znaczną optymalizację kosztów przechowywania i analizy zbiorów Big Data.

Budowa Data Lakehouse
Budowa Data Lakehouse
- To nowoczesne połączenie elastyczności Data Lake (dla danych pod modele LLM) z rygorem, strukturą i bezpieczeństwem znanym z tradycyjnych systemów. Architektura ta tworzy jedyne źródło prawdy (Single Source of Truth), eliminując kosztowne powielanie danych i usprawniając pracę zespołów BI oraz Data Science.

Automatyzacja Pipeline’ów (ELT/ETL)
Automatyzacja Pipeline’ów (ELT/ETL)
- Wdrażamy procesy, które automatycznie czyszczą, standaryzują i przygotowują dane do efektywnego trenowania modeli sztucznej inteligencji. Dzięki wykorzystaniu Data Build Tool (dbt) oraz standardów DataOps, skracamy czas dostarczania gotowych analiz z tygodni do pojedynczych dni.

Real-time Streaming
Real-time Streaming
- Umożliwiamy przetwarzanie danych w momencie ich powstania, co jest niezbędne dla systemów rekomendacyjnych i predykcji zachowań klientów w czasie rzeczywistym. Zamiana raportów wsadowych na streaming danych pozwala firmie podejmować decyzje w oparciu o dane live, reagując na zmiany rynkowe natychmiast.

Specyficzne pod AI, czyli to,
co nas wyróżnia
Wyjdź poza standardową analitykę dzięki unikalnym rozwiązaniom inżynieryjnym, zaprojektowanym z myślą o skalowaniu systemów Generative AI.

Warstwa Semantyczna: Pomagamy budować jednoznaczną warstwę definicji biznesowych wewnątrz Twojej architektury danych. Im dokładniejsza i lepiej zaprojektowana jest ta struktura, tym lepiej radzą sobie agenci AI.
Vector Databases: Przygotowujemy Twoją infrastrukturę pod bazy wektorowe – niezbędne do działania systemów RAG (rozmowa z dokumentami firmowymi).
Data Governance & Quality: Wdrażamy automatyczny monitoring jakości danych, abyś miał pewność, że AI nie wyciąga błędnych wniosków na podstawie błędnych danych.

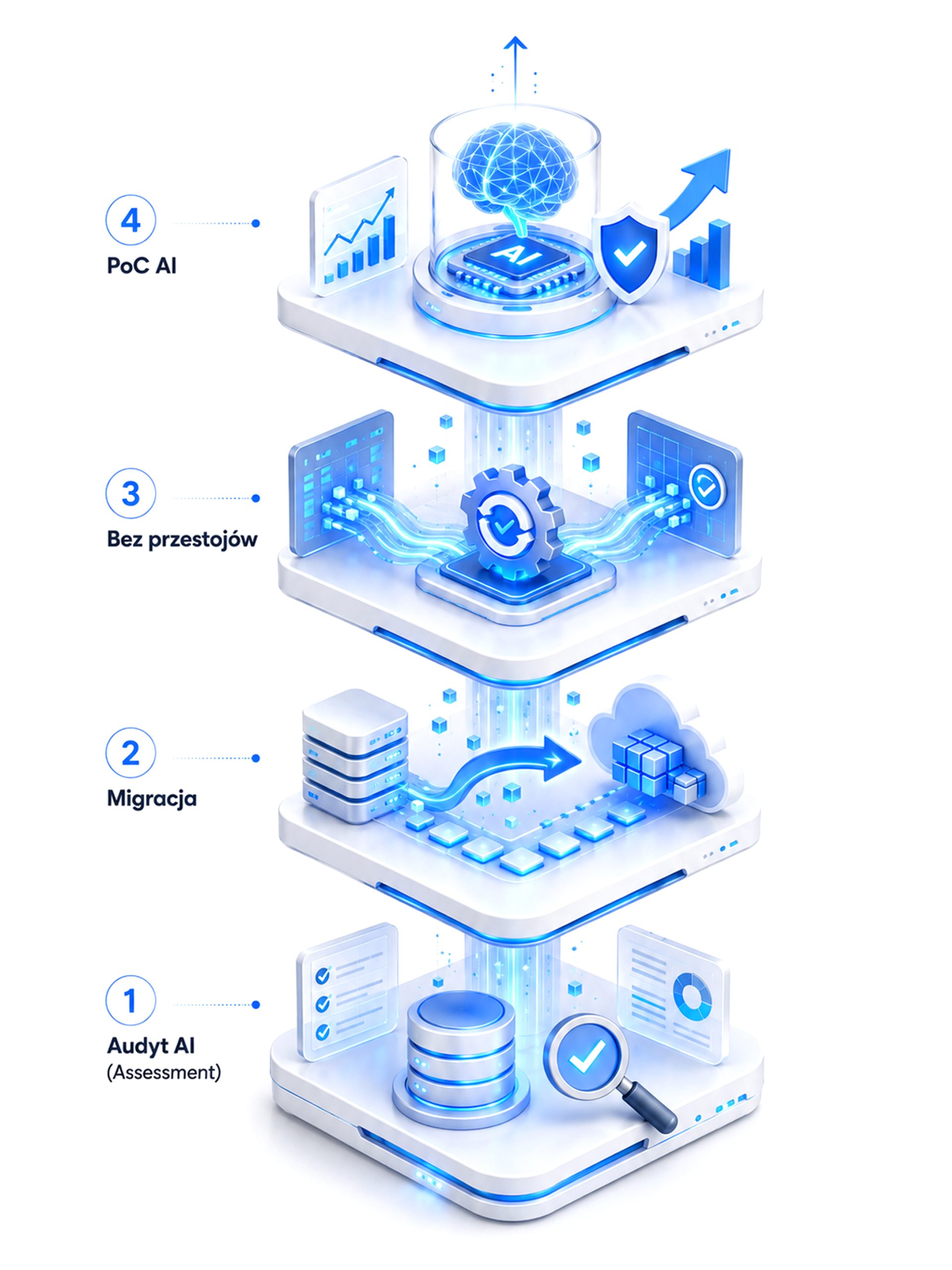
Jak przechodzimy przez modernizację?
Zmień chaos w danych w precyzyjne narzędzia sztucznej inteligencji dzięki naszej sprawdzonej metodologii modernizacji.
AI Readiness Assessment
Audytujemy Twój obecny stack technologiczny, aby zidentyfikować wąskie gardła i wyznaczyć precyzyjną mapę drogową wdrożeń z realnym potencjałem ROI.
Strategia Migracji
Projektujemy bezpieczną ścieżkę przejścia do nowoczesnej architektury, która minimalizuje ryzyko utraty danych i zapewnia pełną kontrolę nad kosztami chmurowymi.
Modernizacja „bez przestojów”
Wdrażamy nowe rozwiązania równolegle do Twoich operacji, gwarantując ciągłość raportowania biznesowego przy jednoczesnej budowie nowoczesnych fundamentów pod AI.
Uruchomienie Pilotowego Modelu AI
Proces wieńczymy wdrożeniem pierwszego modelu (PoC), który w praktyce udowadnia wartość nowej struktury i przynosi wymierne korzyści biznesowe od pierwszego dnia.
Zbudujmy fundament, który realnie zarabia
Formularz kontaktowyPoznaj historie sukcesu naszych klientów

Pomogliśmy Celsium zbudować hurtownię danych, która zredukowała koszty o 180 000 zł rocznie
Zintegrowaliśmy dane z liczników, SCADA, systemów billingowych i pogodowych w jednej hurtowni na Google Cloud Platform. Stworzyliśmy zaawansowane procesy ETL, mechanizmy kontroli jakości danych i dashboardy w Tableau, wspierające codzienną analizę produkcji i zużycia ciepła.
Efekt? Wykrywanie awarii liczników w 1 dzień (wcześniej miesiąc), 3× dziennie aktualizowane dane operacyjne i znaczne oszczędności dzięki optymalizacji źródeł ciepła i lepszemu bilansowaniu popytu.

Zbudowaliśmy nowoczesną hurtownię danych w GCP dla Polskiego Światłowodu Otwartego
Pomogliśmy PŚO zaprojektować i wdrożyć skalowalną architekturę Data Lake na Google Cloud Platform. Zintegrowaliśmy 13 źródeł danych, stworzyliśmy automatyczne procesy ELT, zabezpieczenia dostępu i model danych będący jednym źródłem prawdy w organizacji.
Efekt? Niezależność w raportowaniu, szybka integracja nowych systemów, gotowość na przyszłe potrzeby i oszczędność kosztów dzięki eliminacji infrastruktury on-premise.

Pomogliśmy AMS wykorzystać dane z nośników DOOH i utrzymać pozycję lidera reklamy zewnętrznej
Zbudowaliśmy nowoczesny ekosystem danych dla AMS – lidera reklamy OOH i DOOH. Połączyliśmy dane z nośników, systemów wewnętrznych, Proxi.cloud i CitiesAI, tworząc jednolitą hurtownię danych w BigQuery z analizą w czasie zbliżonym do rzeczywistego.
Efekt? Targetowanie oparte na danych, automatyzacja kampanii, lepsze wyniki dla klientów i umocnienie pozycji rynkowej dzięki programmatic buying w oparciu o rzeczywisty zasięg.

Pomogliśmy Tutlo zautomatyzować integrację danych i zbudować nowoczesne ETL w czasie rzeczywistym
We współpracy z zespołem Tutlo zaprojektowaliśmy i wdrożyliśmy architekturę integracji danych opartą o bezserwerowe komponenty Google Cloud. System umożliwia synchronizację danych z dziesiątek źródeł – w tym CRM – z pełnym monitoringiem, automatyzacją CI/CD i gotowością do dalszej skalowalności.
Efekt? Stabilny i elastyczny ekosystem danych, gotowy na automatyzację procesów, projekty ML i dynamiczny rozwój platformy edukacyjnej.

Pomogliśmy FunCraft prognozować ROI i optymalizować budżety UA w branży mobile gaming
Dla amerykańskiego studia gier wdrożyliśmy kompleksowe rozwiązanie BI, integrując dane z Adjust, sklepów i platform reklamowych do hurtowni BigQuery. Zbudowaliśmy zaawansowane dashboardy w Looker Studio oraz modele predykcyjne ROI, które umożliwiają podejmowanie trafnych decyzji budżetowych – nawet przy długim cyklu zwrotu z inwestycji.
Efekt? Zespół marketingu FunCraft działa szybciej, skuteczniej i z pełną kontrolą nad danymi.

Twoje dane kryją w sobie potencjał. Zapytaj nas, jak go wykorzystać
Dlaczego Alterdata?
Łączymy doświadczenie ekspertów, szeroką znajomość technologii i elastyczne podejście do współpracy, aby tworzyć rozwiązania danych realnie dopasowane do potrzeb Twojej organizacji.
Kompleksowa realizacja End-to-End
Prowadzimy cały proces: od doradztwa i wyboru technologii, przez budowę hurtowni danych, po rozwój, utrzymanie i optymalizację rozwiązań. Dzięki temu klient otrzymuje spójne wsparcie na każdym etapie pracy z danymi, bez konieczności koordynowania wielu niezależnych dostawców.
Ekspercki zespół danych
Łączymy kompetencje inżynierów danych, analityków, data scientistów, architektów IT i konsultantów biznesowych, aby odpowiadać zarówno na potrzeby technologiczne, jak i biznesowe. Nasz zespół pomaga przełożyć cele organizacji na konkretne rozwiązania, które realnie wspierają decyzje i rozwój firmy.
Neutralność technologiczna
Dobieramy narzędzia do celu, a nie odwrotnie. Pracujemy z popularnymi technologiami chmurowymi i analitycznymi, m.in. Google Cloud, Azure, AWS, Snowflake, Databricks, Power BI, Tableau czy Looker. Dzięki szerokiej znajomości narzędzi rekomendujemy rozwiązania najlepiej dopasowane do sytuacji klienta, zamiast forsować jedną technologię.
Elastyczny model współpracy
Oferujemy wsparcie dokładnie wtedy, gdy go potrzebujesz, od pojedynczych specjalistów po model Data Team as a Service, bez konieczności budowania pełnego zespołu wewnętrznie. Pozwala to szybko zwiększać kompetencje organizacji i korzystać z wiedzy ekspertów w zakresie dopasowanym do aktualnych potrzeb.
Rozwiązania dopasowane do biznesu
Projektujemy usługi i architekturę pod konkretne wymagania, budżet, branżę, wielkość firmy oraz cele biznesowe klienta. Każde wdrożenie traktujemy indywidualnie, aby technologia wspierała procesy, sposób pracy i priorytety danej organizacji.
Bezpieczna architektura
Tworzymy skalowalne, bezpieczne rozwiązania gotowe na rozwój organizacji, rosnącą ilość danych i migrację do nowoczesnych środowisk chmurowych. Dbamy o kontrolę dostępu, stabilność i możliwość dalszej rozbudowy, aby platforma danych mogła rozwijać się razem z firmą.
Tech stack: fundament naszej pracy
Poznaj narzędzia i technologie, które napędzają rozwiązania tworzone przez Alterdata.

Google Cloud Storage umożliwia przechowywania danych w chmurze i wydajność, elastyczne zarządzanie dużymi zbiorami danych. Zapewnia łatwy dostęp do danych i wsparcie zaawansowanych analiz.

Azure Data Lake Storage to usługa przechowywania oraz analizowania danych ustrukturyzowanych i nieustrukturyzowanych w chmurze, stworzona przez Microsoft. Data Lake Storage jest skalowalne i obsługuje różne formaty danych.

Amazon S3 to usługa chmurowa do bezpiecznego przechowywania danych o praktycznie nieograniczonej skalowalności. Jest wydajna i zapewnia spójność oraz łatwy dostępu do danych.

Databricks to chmurowa platforma analityczna, łącząca inżynierię i analizę danych oraz machine learning i modele predykcyjne. Z wysoką wydajnością przetwarza ona także duże zbiory danych.

Microsoft Fabric to zintegrowane środowisko analityczne, łączące w różne narzędzia, takie jak Power BI, Data Factory, czy Synapse. Platforma obsługuje cały cyklu życia danych, integrację, przetwarzanie, analizę i wizualizację wyników.
Google Big Lake to usługa, która łączy w sobie cechy hurtowni oraz jezior danych i ułatwia zarządzanie danymi w różnych formatach oraz lokalizacjach. Pozwala także przetwarzać duże zbiory danych bez przenoszenia między systemami.

Google Cloud Dataflow do usługa przetwarzania dużych ilości danych oparta na Apache Beam. Wspiera rozproszone przetwarzanie danych w czasie rzeczywistym oraz zaawansowane analizy

Azure Data Factory to usługa integracji danych w chmurze, która automatyzuje przepływy danych i orkiestruje procesy przetwarzania. Umożliwia łączenie danych ze źródeł chmurowych i lokalnych do przetwarzania w jednym środowisku.

Apache Kafka przetwarza w czasie rzeczywistym strumienie danych i wspiera zarządzanie dużymi ilościami danych z różnych źródeł. Pozwala analizować zdarzenia natychmiast po ich wystąpieniu.
Pub/Sub służy do przesyłania wiadomości między aplikacjami, przetwarzania strumieni danych w czasie rzeczywistym, ich analizy i tworzenia kolejek komunikatów. Dobrze integruje się z mikrousługami oraz architekturami sterowanymi zdarzeniami (EDA).
Google Cloud Run obsługuje aplikacje kontenerowe w skalowalny i zautomatyzowany sposób, przez co optymalizuje koszty oraz zasoby. Pozwala na elastyczne i wydajne zarządzanie aplikacjami w chmurze, zmniejszając obciążenie pracą.

Azure Functionsto inne rozwiązanie bezserwerowe, które uruchamia kod w reakcji na zdarzenia, eliminując potrzebę zarządzania serwerami. Jego inne zalety to możliwość automatyzowania procesów oraz integrowania różnych usług.

AWS Lambda to sterowana zdarzeniami, bezserwerowa funkcja jako usługa (FaaS), która umożliwia automatyczne uruchamianie kodu w odpowiedzi na zdarzenia. Pozwala uruchamiać aplikacje bez infrastruktury serwerowej.

Azure App Service to platforma chmurowa, służąca do uruchamiania aplikacji webowych i mobilnych. Oferuje automatyczne skalowanie zasobów i integrację z narzędziami DevOps, (np. GitHub, Azure DevOps)

Snowflake to platforma, która umożliwia przechowywanie, przetwarzanie i analizowanie dużych zbiorów danych w chmurze. Jest łatwo skalowalna, wydajna, zapewnia też spójność oraz łatwy dostępu do danych.

Amazon Redshift to hurtownia danych w chmurze, która umożliwia szybkie przetwarzanie i analizowanie dużych zbiorów danych. Redshift oferuje także tworzenie złożonych analiz i raportów z danych w czasie rzeczywistym.
BigQuery to skalowalna platforma analizy danych od Google Cloud. Umożliwia ona szybkie przetwarzanie dużych zbiorów danych, analitykę oraz zaawansowane raportowanie. Ułatwia dostęp do danych dzięki integracji z różnymi ich źródłami.

Azure Synapse Analytics to platforma łącząca hurtownię danych, przetwarzanie big data oraz analitykę w czasie rzeczywistym. Umożliwia przeprowadzanie skomplikowanych analiz na dużych wolumenach danych.

Data Build Tool umożliwia łatwą transformację i modelowanie danych bezpośrednio w bazach danych. Pozwala tworzyć złożone struktury, automatyzować procesy i zarządzać modelami danych w SQL.

Dataform jest częścią Google Cloud, która automatyzuje transformację danych w BigQuery, w oparciu o język zapytań SQL. Wspiera bezserwerową orkiestrację strumieni danych i umożliwia pracę zespołową z danymi.
Pandas to biblioteka struktur danych oraz narzędzi analitycznych w języku Python. Jest przydatna w manipulowaniu danymi i analizach. Pandas jest używana szczególnie w statystyce i machine learningu.

PySpark to interfejs API dla Apache Spark, który pozwala przetwarzać duże ilości danych w rozproszonym środowisku, w czasie rzeczywistym. To narzędzie jest proste w użyciu oraz wszechstronne w działaniu.

Looker Studio to narzędzie służące do eksploracji i zaawansowanej wizualizacji danych pochodzących z różnych źródeł, w formie czytelnych raportów, wykresów i dashboardów. Ułatwia współdzielenie danych oraz wspiera równoczesną pracę wielu osób, bez potrzeby kodowania.

Tableau, aplikacja od Salesforce, to wszechstronne narzędzie do analiz i wizualizacji danych, idealne dla osób szukających intuicyjnych rozwiązań. Cenione za wizualizacje danych przestrzennych i geograficznych, szybkie identyfikowanie trendów oraz dokładność analiz danych.
Power BI, platforma Business Intelligence koncernu Microsoft, wydajnie przekształca duże ilości danych w czytelne, interaktywne wizualizacje i przystępne raporty. Łatwo integruje się z różnymi źródłami danych oraz monitoruje KPI w czasie rzeczywistym.
Looker to platforma chmurowa do Business Intelligence oraz analityki danych, która pozwala eksplorować, udostępniać oraz wizualizować dane i wspiera procesy decyzyjne. Looker wykorzystuje też uczenie maszynowe do automatyzacji procesów i tworzenia predykcji.
Terraform to narzędzie open-source, które pozwala na zarządzanie infrastrukturą jako kodem oraz automatyczne tworzenie i aktualizację zasobów w chmurze. Wspiera efektywne kontrolowanie infrastruktury, minimalizuje ryzyko błędów, zapewnia transparentność i powtarzalność procesów.

GCP Workflows automatyzuje przepływy pracy w chmurze, a także ułatwia zarządzanie procesami łączącymi usługi Google Cloud. To narzędzie pozwala oszczędzać czas dzięki unikaniu dublowania działań, poprawia jakości pracy, eliminując błędy, oraz umożliwia wydajne zarządzanie zasobami.

Apache Airflow zarządza przepływem pracy, umożliwia planowanie, monitorowanie oraz automatyzację procesów ETL i innych zadań analitycznych. Daje też dostęp do statusu zadań ukończonych i bieżących oraz wgląd w logi ich wykonywania.

Rundeck to narzędzie open-source do automatyzacji, które umożliwia planowanie, zarządzanie oraz uruchamianie zadań na serwerach. Pozwala na szybkie reagowanie na zdarzenia i wspiera optymalizację zadań administracyjnych.

Python to kluczowy język programowania w uczeniu maszynowym (ML). Dostarcza bogaty ekosystem bibliotek, takich jak TensorFlow i scikit-learn, umożliwiając tworzenie i testowanie zaawansowanych modeli.

BigQuery ML pozwala na budowę modeli uczenia maszynowego bezpośrednio w hurtowni danych Google wyłącznie za pomocą SQL. Zapewnia szybki time-to-market, jest efektywny kosztowo, umożliwia też szybką pracę iteracyjną.

R to język programowania do obliczeń statystycznych i wizualizacji danych, do tworzenia oraz testowania modeli uczenia maszynowego. Umożliwia szybkie prototypowanie oraz wdrażanie modeli ML.

Vertex AI służy do deplymentu, testowania i zarządzania gotowymi modeli ML. Zawiera także gotowe modele przygotowane i trenowane przez Google, np. Gemini. Vertex AI wspiera też niestandardowe modele TensorFlow, PyTorch i inne popularne frameworki.
FAQ
Czy modernizacja hurtowni danych jest niezbędna do wdrożenia AI?
Tak, ponieważ tradycyjne systemy on-premise nie oferują skalowalności mocy obliczeniowej niezbędnej do trenowania modeli ML. Modernizacja pozwala na stworzenie fundamentu danych, który eliminuje silosy i dostarcza wysokiej jakości informacje w czasie rzeczywistym.
Ile kosztuje migracja hurtowni danych do chmury (np. BigQuery)?
Koszt zależy od wolumenu danych i złożoności procesów, jednak model pay-as-you-go w chmurze pozwala na znaczną optymalizację kosztów IT. Dzięki nowoczesnej architekturze płacisz tylko za realne zużycie zasobów, unikając kosztownego utrzymania własnych serwerów.
Co to jest Data Lakehouse i dlaczego jest lepszy dla AI?
Data Lakehouse łączy zalety jeziora danych (elastyczność dla plików PDF, wideo pod LLM) z porządkiem hurtowni (struktury tabelaryczne). Jest to rozwiązanie idealne pod AI, ponieważ zapewnia Single Source of Truth dla analityków BI oraz inżynierów Machine Learning.
Jak zapewnić bezpieczeństwo danych firmowych przy wdrażaniu modeli RAG?
Stosujemy prywatne bazy wektorowe oraz bezpieczne połączenia wewnątrz Twojej chmury, dzięki czemu dane nigdy nie opuszczają chronionego środowiska. Wdrażamy rygorystyczny Data Governance, który gwarantuje, że modele AI mają dostęp tylko do autoryzowanych zasobów.
Jak długo trwa proces modernizacji architektury danych?
Pierwsze efekty w postaci Proof of Concept (PoC) dostarczamy zazwyczaj w ciągu 4-6 tygodni. Pełna migracja i automatyzacja pipeline’ów ELT zależy od skali, ale nasze podejście bez przestojów pozwala na ewolucyjne wdrażanie zmian bez paraliżu firmy.
Czy moje stare dane nadają się do zasilania sztucznej inteligencji?
Większość danych wymaga „uzdatnienia” – dlatego kluczowym etapem jest automatyzacja jakości danych (Data Quality). Wdrażamy procesy czyszczenia i denormalizacji danych, które zamieniają surowe informacje w wartościowe paliwo dla algorytmów AI.
Co to są bazy wektorowe i czy ich potrzebuję?
Bazy wektorowe (np. Pinecone, Weaviate czy natywne rozwiązania w BigQuery) są niezbędne, jeśli planujesz wdrożenie systemów rozmowy z dokumentami (RAG). Pozwalają one AI błyskawicznie przeszukiwać kontekstowo tysiące plików firmowych.
Jakie są korzyści biznesowe (ROI) z modernizacji hurtowni danych?
Główne korzyści to skrócenie czasu dostarczania analiz (Time-to-Market), spadek kosztów operacyjnych oraz możliwość wdrażania analityki predykcyjnej. Firmy z nowoczesnym stackiem danych podejmują decyzje o 30-50% szybciej niż konkurencja.
Czy modernizacja wpłynie na działanie moich obecnych raportów w Power BI / Tableau?
Nie. Nasza metodologia zakłada modernizację bez przestojów, co oznacza, że nowe źródła danych są podpinane równolegle. Twoje obecne dashboardy biznesowe pozostają aktywne, zyskując jedynie na szybkości i dokładności danych.
Czym różni się podejście Alterdata od standardowych firm IT?
Nie jesteśmy tylko firmą od migracji – jesteśmy partnerem AI-first. Budujemy architekturę danych z myślą o ich użyteczności dla modeli produkcyjnych, wdrażając od razu takie rozwiązania jak Feature Store czy zaawansowany MLOps.