




























Professional Data Integration Services
Integrating data from various sources is part of comprehensive data engineering services, which improves its quality, eliminates manual work, and enhances the accuracy of analytics.
Let’s talk
We empower leaders:









Benefits of Modern Data
Integration Platforms
With data integration platforms, all data is combined into a centralized system, enhancing a company’s flexibility and responsiveness to business needs.

No data silos
Source integration breaks down barriers between departments, enabling consistent and integrated data access for users across the organization. By using advanced data integration software, teams can access, process, and analyze datasets, reducing errors and improving decision-making.
Quick access to data
Data integration solutions enable the efficient management of data flows, allowing the extraction and processing of datasets without manual intervention. This eliminates inefficiencies, reduces costs, and minimizes human error. Centralized databases allow faster analytics, reporting, and easier access for users.
Better system integration
Consolidating data in one place ensures better information quality not only for people but also for company systems, whose performance largely depends on this data. This also facilitates smooth data migration, maintaining data integrity and ensuring business continuity during the process.
Higher quality data
Consistent data formats, no duplicates, or false data lead to greater precision in work. It also enables using data to streamline business processes, such as personalizing customer experiences.
Faster and more accurate insights
Integrating relevant data sources and formats accelerates analysis and increases the precision of insights. It supports the identification of threats and opportunities, and highlights areas for improvement, such as customer service.
Shorter time-to-market
Using data integration platforms and automated processes, businesses can speed up access to insights and accelerate their create, transform, load (ETL) pipelines. This allows companies to deliver products and services before the competition does.
Integrate all your data in one place
Let’s talkConsolidate scattered data
into a single, secure source of truth
4 problems in your company,
that you can easily solve by integrating your data sources:

Incorrect data and lack of integration
Without unified data systems, poor quality and integration errors lead to faulty analysis. A robust data integration solution and optimized data warehousing ensure accurate, actionable data.
Manual work reduces efficiency
Manually combining datasets wastes time and increases errors. Data integration software automates workflows, boosting efficiency.
Difficult access to information
Lack of data centralization creates conflicting sources of truth. A single integration platform ensures reliable, accessible databases for all users.
Unnecessary expenses
Without integration, you can’t eliminate certain systems that are completely unnecessary when optimizing.

Our data integration philosophy
built to evolve with your business
We treat data integration as a continuous capability, not a one-off technical task. Our role is to help companies build reliable, scalable, and measurable data foundations.

Source-specific integration: We adapt integration methods to each data source — from databases and APIs to files, corporate systems, and event streams.
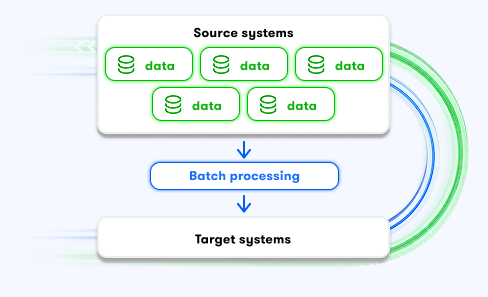
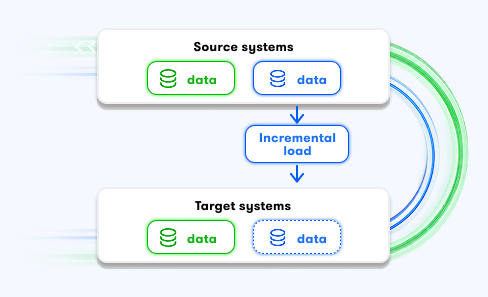
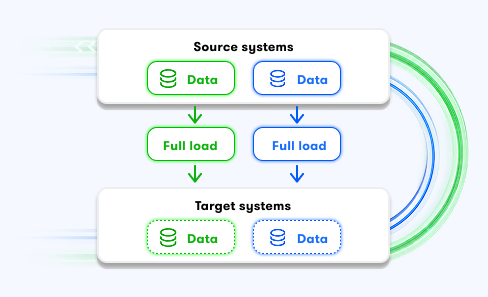
Right ELT / ETL strategy: We choose the right processing model for every use case: batch, streaming, full load, incremental updates, ELT, or ETL.
Modern tooling approach: We help select and implement the right integration software — ready-made, custom-built, or combined into a scalable architecture.
Built-in validation: We design quality checks and monitoring mechanisms that help detect errors early and keep data consistent across systems.
Trusted data foundation: We turn fragmented data into reliable information that supports better decisions, measurable outcomes, and long-term growth.
Let’s integrate your disparate systems into one
Integrate your data nowMethods for integrating data sources
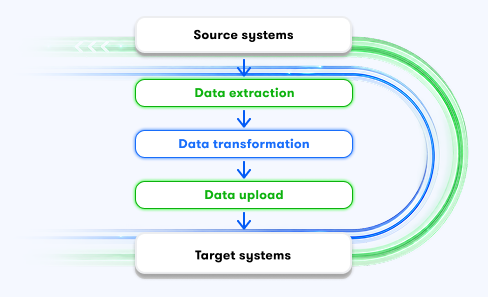
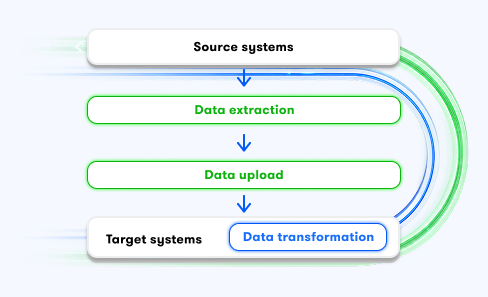
ELT (Extract, load, transform)
ELT (Extract, Load, Transform) processes represent a different approach to data integration; they involve extracting data and loading it into a data warehouse, where it is then transformed. ELT processes are used, among other things, in cloud solutions and machine learning.

Your data holds great potential. Ask us how to make the most of it
Why should choose Alterdata?
We combine expert experience, extensive technical knowledge, and a flexible approach to collaboration to create data solutions that are truly tailored to your organization’s needs.
Comprehensive End-to-End Implementation
We manage the entire process: from consulting and technology selection, through data warehouse construction, to the development, maintenance, and optimization of solutions. This ensures that our clients receive consistent support at every stage of their data-related work, without having to coordinate multiple independent vendors.
Data Expert Team
We bring together the expertise of data engineers, analysts, data scientists, IT architects, and business consultants to address both technological and business needs. Our team helps translate an organization’s goals into concrete solutions that effectively support decision-making and business growth.
Technology Neutrality
We choose tools based on the goal, not the other way around. We work with popular cloud and analytics technologies, including Google Cloud, Azure, AWS, Snowflake, Databricks, Power BI, Tableau, and Looker. Thanks to our extensive knowledge of these tools, we recommend the solutions best suited to the client’s situation, rather than pushing a single technology.
Flexible Model of Collaboration
We offer support exactly when you need it, ranging from individual specialists to a Data Team as a Service model, without the need to build a full in-house team. This allows you to quickly expand your organization’s capabilities and leverage expert knowledge in a way that aligns with your current needs.
Business-Specific Solutions
We design services and architecture tailored to specific requirements, budgets, industries, company sizes, and business objectives. We treat each implementation as a unique case to ensure that the technology supports the processes, workflows, and priorities of the organization in question.
Secure Architecture
We create scalable, secure solutions designed to support organizational growth, handle increasing data volumes, and facilitate migration to modern cloud environments. We ensure access control, stability, and scalability so that the data platform can grow alongside your business.
Tech stack: the foundation of
our work
Discover the tools and technologies that power the solutions created by Alterdata.

Google Cloud Storage enables data storage in the cloud and provides high performance, offering flexible management of large datasets. It ensures easy data access and supports advanced analytics.

Azure Data Lake Storage is a service for storing and analyzing structured and unstructured data in the cloud, created by Microsoft. Data Lake Storage is scalable and supports various data formats.

Amazon S3 is a cloud service for securely storing data with virtually unlimited scalability. It is efficient, ensures consistency, and provides easy access to data.

Databricks is a cloud-based analytics platform that combines data engineering, data analysis, machine learning, and predictive models. It processes large datasets with high efficiency.

Microsoft Fabric is an integrated analytics environment that combines various tools such as Power BI, Data Factory, and Synapse. The platform supports the entire data lifecycle, including integration, processing, analysis, and visualization of results.
Google BigLake is a service that combines the features of both data warehouses and data lakes, making it easier to manage data in various formats and locations. It also allows processing large datasets without the need to move them between systems.

Google Cloud Dataflow is a data processing service based on Apache Beam. It supports distributed data processing in real-time and advanced analytics.

Azure Data Factory is a cloud-based data integration service that automates data flows and orchestrates processing tasks. It enables seamless integration of data from both cloud and on-premises sources for processing within a single environment.

Apache Kafka processes real-time data streams and supports the management of large volumes of data from various sources. It enables the analysis of events immediately after they occur.
Pub/Sub is used for messaging between applications, real-time data stream processing, analysis, and message queue creation. It integrates well with microservices and event-driven architectures (EDA).
Google Cloud Run supports containerized applications in a scalable and automated way, optimizing costs and resources. It allows flexible and efficient management of cloud applications, reducing the workload.

Azure Functions is another serverless solution that runs code in response to events, eliminating the need for server management. Its other advantages include the ability to automate processes and integrate various services.

AWS Lambda is an event-driven, serverless Function as a Service (FaaS) that enables automatic execution of code in response to events. It allows running applications without server infrastructure.

Azure App Service is a cloud platform used for running web and mobile applications. It offers automatic resource scaling and integration with DevOps tools (e.g., GitHub, Azure DevOps).

Snowflake is a platform that enables the storage, processing, and analysis of large datasets in the cloud. It is easily scalable, efficient, and ensures consistency as well as easy access to data.

Amazon Redshift is a cloud data warehouse that enables fast processing and analysis of large datasets. Redshift also offers the creation of complex analyses and real-time data reporting.
BigQuery is a scalable data analysis platform from Google Cloud. It enables fast processing of large datasets, analytics, and advanced reporting. It simplifies data access through integration with various data sources.

Azure Synapse Analytics is a platform that combines data warehousing, big data processing, and real-time analytics. It enables complex analyses on large volumes of data.

Data Build Tool simplifies data transformation and modeling directly in databases. It allows creating complex structures, automating processes, and managing data models in SQL.

Dataform is part of the Google Cloud Platform, automating data transformation in BigQuery using SQL query language. It supports serverless data stream orchestration and enables collaborative work with data.
Pandas is a data structure and analytical tool library in Python. It is useful for data manipulation and analysis. Pandas is used particularly in statistics and machine learning.

PySpark is an API for Apache Spark that allows processing large amounts of data in a distributed environment, in real-time. This tool is easy to use and versatile in its functionality.

Looker Studio is a tool used for exploring and advanced data visualization from various sources, in the form of clear reports, charts, and interactive dashboards. It facilitates data sharing and supports simultaneous collaboration among multiple users, without the need for coding.

Tableau, an application from Salesforce, is a versatile tool for data analysis and visualization, ideal for those seeking intuitive solutions. It is valued for its visualizations of spatial and geographical data, quick trend identification, and data analysis accuracy.
Power BI, Microsoft’s Business Intelligence platform, efficiently transforms large volumes of data into clear, interactive dashboards and accessible reports. It easily integrates with various data sources and monitors KPIs in real-time.
Looker is a cloud-based Business Intelligence and data analytics platform that enables data exploration, sharing, and visualization while supporting decision-making processes. Looker also leverages machine learning to automate processes and generate predictions.
Terraform is an open-source tool that allows for infrastructure management as code, as well as the automatic creation and updating of cloud resources. It supports efficient infrastructure control, minimizes the risk of errors, and ensures transparency and repeatability of processes.

GCP Workflows automates workflows in the cloud and simplifies the management of processes connecting Google Cloud services. This tool saves time by avoiding the duplication of tasks, improves work quality by eliminating errors, and enables efficient resource management.

Apache Airflow manages workflows, enabling scheduling, monitoring, and automation of ETL processes and other analytical tasks. It also provides access to the status of completed and ongoing tasks, as well as insights into their execution logs.

Rundeck is an open-source automation tool that enables scheduling, managing, and executing tasks on servers. It allows for quick response to events and supports the optimization of administrative tasks.

Python is a programming language, also used for machine learning, with libraries dedicated to machine learning (e.g., TensorFlow and scikit-learn). It is used for creating and testing machine learning models.

BigQuery ML allows the creation of machine learning models directly within Google’s data warehouse using only SQL. It provides a fast time-to-market, is cost-effective, and enables rapid iterative work.

R is a programming language primarily used for statistical calculations, data analysis, and visualization, but it also has modules for training and testing machine learning models. It enables rapid prototyping and deployment of machine learning.

Vertex AI is used for deploying, testing, and managing machine learning models. It also includes pre-built models prepared and trained by Google, such as Gemini. Vertex AI also supports custom models from TensorFlow, PyTorch, and other popular frameworks.
Got a question about
Data Integration Services?
How long does data source integration take?
The time required for data integration depends on the complexity of the project, the number of corporate data sources, and the choice between using ready-made solutions or those developed specifically for the client. The benefits, such as faster access to data and greater trust in its accuracy, are usually visible within a few weeks after the work begins.
How will I know that the data source integration is successful, and which KPIs should be set?
Key KPIs in this context include increasing the reliability of ETL/ELT processes, reducing errors in reports, and improving the efficiency of operations that utilize integrated data. Together, we will select indicators specific to your company so that you can monitor how data integration translates into making more accurate decisions.
Is data source integration a solution only for large companies?
No, every organization that uses data from its systems should ensure its quality. Establishing a single source of truth and making data access easier for employees improves efficiency in both small and large companies, enabling them to make better business decisions more quickly.
Will new technologies be compatible with our technology?
Our integration solutions are designed with compatibility with both existing and future technologies in mind. We adapt to your requirements, ensuring flexibility and scalability.
Do I need any specific expertise in my organization for this service?
You don’t need to have specialized expertise within your organization. Our team of experts handles the entire implementation process, providing full support and training for your team.
Does an external analyst or data engineer have access to all the information in our company?
We ensure complete data security. Access to information is strictly controlled, and our experts only have access to the data necessary for project execution, adhering to the highest protection standards. We do not extract data; it is stored exclusively on the client’s side.
What if data quality issues arise in the future?
Our engineers provide ongoing support in monitoring and improving data quality. In case of issues, they deliver quick and effective solutions to maintain data integrity.
Is the company technologically objective and will it take our technology preferences into account?
Alterdata is technologically independent. Our recommendations are always based on your preferences and the best solutions available on the market, ensuring optimal effectiveness and alignment with your requirements. While we partner with many technology providers, we do not sell their products. This gives us maximum objectivity in selecting the most suitable technology to address your problem.