



















Introduction: Paper & PDF Chaos vs. Digital Precision
For every team dealing with processing paper documents, PDF scans, or unstructured resources, one thing is clear: this is not an intellectual or technological problem but a problem of scale. Tens (sometimes thousands) of formats, lack of standards, annexes and administrative decisions, altogether hundreds of thousands of documents, millions of pages. At such volumes, even the best-organized operational teams buckle under the weight of manual work. The system is designed to handle a wide variety of business documents, such as PDFs, scanned images, and other structured materials commonly used in business settings.
This is where AI comes into play. But not the kind that does everything on its own. Only the kind that, when properly guided, extracts the needed information faster, cheaper, and often with fewer errors than a human. Implementing modern AI-based solutions allows effective document management and accelerates business processes – these technologies enable automation of key stages of document processing, from data extraction to analysis. This helps relieve people and speed up decision-making. Automating repetitive tasks with AI solutions streamlines document processing and reduces operational costs by minimizing manual intervention and increasing efficiency. In this article, I will show you how we used GenAI models and GCP tools to process tens of thousands of documents in one of Alterdata’s projects and what practical insights you can gain for your organization. That’s why following best practices in building and deploying ML models is crucial.
Where we started: scale and chaos
We started like many organizations: with a digital archive that was actually a collection of over 40,000 documents in various formats (PDF, JPG scans, TIFF), with different names, lengths, and no common structure. Many of these files contained unstructured data, which had no defined structure, significantly complicating their analysis and further use. The documents contained sensitive data, administrative decisions, contract annexes, location consents, cost invoices, technical reports, acceptance protocols, legal letters, and many other categories.
This mix of formats and content made traditional approaches (OCR – optical character recognition + regex + manual verification) impossible to work within an acceptable time and budget. In the case of unstructured data and lack of defined document structure, advanced tools for document processing automation are necessary to avoid engaging in complex processes or lengthy model training. Deep learning techniques now play a crucial role in enhancing the accuracy and efficiency of recognizing text and extracting information from unstructured and semi-structured documents, making intelligent document processing far more effective than traditional methods. We should try to take steps to stop it and decide when to perform them.

Proof of Concept: How will Generative AI handle document analysis?
We started with a two-week PoC on a selected sample of 500 documents. It was not just a quick demonstration – we worked intensively on this stage: iterating approaches, testing different prompt variants, and evaluating how the model handles unusual structures, low-quality scans, or inconsistent document language. In this process, we used natural language processing techniques and machine learning to increase the precision and efficiency of automation.
Goal: to check if the model (in this case Google Gemini + GCP Functions) can:
- recognize the document type (e.g., location decision vs. annex vs. contract),
- extract data and extract information (such as case numbers, dates, locations, pages, contractors) from documents using AI-driven tools for text recognition and data extraction,
- process documents of varied structure and quality,
- standardize output data into tabular form (BigQuery).
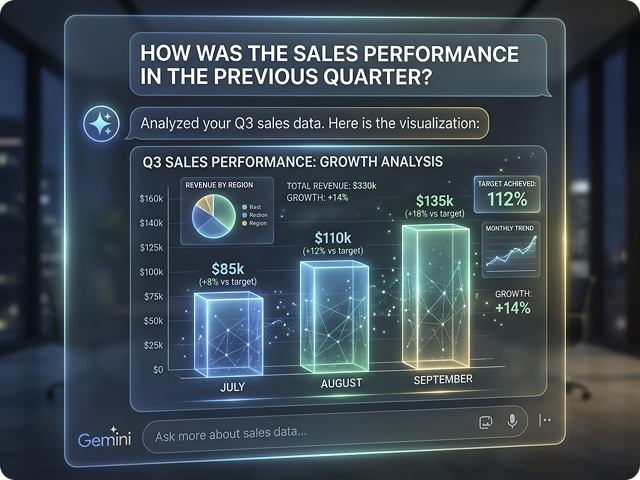
Results? After two weeks of testing, the model achieved over 90% accuracy in document classification and about 95% effectiveness in extracting data from key fields. Considering the diversity of formats, layouts, and source quality – this result was deemed good enough to proceed.
Document analysis and data analysis, as key functions of AI tools used in the project, allowed automatic extraction and interpretation of information from various document types, significantly streamlining the processing workflow. The system efficiently processes multiple documents at once and ensures that only relevant information is extracted and validated to meet specific business needs.
Architecture: simplicity that scales
The final solution was built based on:
- Google Cloud Storage for document storage,
- Cloud Functions as orchestration and model invocation controller,
- Gemini (Vertex AI) for classification, extraction, and splitting of multi-page files,
- BigQuery as the target storage for structured data,
- plus an analytical dashboard and interface for result validation and inspection.
The entire system is based on cloud software providing flexibility, scalability, and easy integration with other systems such as ERP or CRM. The solution features seamless integration capabilities, allowing real-time data processing and analysis across various platforms. It also allows integrating various data sources, enabling consistent preparation of information for further analysis.

CThe whole design was thought to withstand project realities: repetitive tests, variable data, and non-obvious cases.
- Handling iterative corrections (dozens of prompt attempts, adjusting logic for exceptions, edge-case validation) was fundamental.
- The architecture had to consider a model of work where AI supports humans but does not operate autonomously – hence every decision was verifiable.
- The system supports real-time document processing, enabling immediate data analysis and validation and effective document management throughout the process.
- We also prepared everything for large scale – batch processing without freezing on a single error and without manual intervention for each file, which improves process automation. The system is also optimized for efficient processing of single documents within larger workflows.
The analytical dashboard allows monitoring processing results and automation efficiency.
Additionally, the solution enables the use of custom models to analyze PDF files, forms (both printed and handwritten), and emails, allowing precise data extraction according to client needs. The platform can also transform data from various document types to enhance workflows and improve data management processes.
Data Security
In the era of digital transformation, data security becomes one of the most important aspects of document analysis. Processing large volumes of documents, often containing sensitive data, requires not only effective extraction tools but also solutions ensuring full protection of information. Every company implementing process automation and document management should ensure that data access is limited to authorized users only. The tools we use do not share or use document data for any other purposes, ensuring user control and confidentiality.
It is crucial to use software that guarantees security at every stage – from document storage, through processing, to integration with other systems. Data encryption, access control, and regular security audits are today standards that protect the company from unauthorized access and information loss. At Alterdata, we always prioritize solutions that not only accelerate document analysis but also guarantee full data security for our clients.
Integration with other systems
Effective document analysis and business process automation cannot exist isolated from the rest of the company’s IT ecosystem. It is essential that document management systems are fully integrated with other tools – such as databases, CRM systems, or ERP platforms. Only then is seamless information transfer, fast data search, and automatic report generation possible, which truly accelerates business processes.
Modern solutions, such as APIs or webhooks, allow smooth communication between systems, eliminating the need for manual data transfer and minimizing error risks. This makes document management not only more efficient but also safer. At Alterdata, we always design architecture with easy integration in mind so our clients can fully leverage the potential of their data and tools, regardless of industry or business scale.

Iterations and lessons: no illusions, complex work, and concrete experience
The biggest challenges were neither purely technical nor strictly operational – they appeared precisely at the intersection of technology and practice, where tools are supposed to support business goals realization:
- How to build a matrix of document types that covers all cases?
- How to validate data that often appeared in different forms (e.g., address once shortened, once descriptive)?
- How to decide what the model should always read and what only when possible?
- Training employees and users in AI tools and document processing automation was also necessary to ensure effective implementation and process security. Human input played a crucial role in refining and validating AI-driven document processing, as collaborative oversight and corrections by humans ensured greater accuracy and efficiency.
In total, we went through hundreds of prompt and control logic iterations before the team considered data quality “production-ready.” During these iterations, we performed various tasks related to text analysis and recognition, including key information recognition and removing irrelevant data such as branding or distortions to improve process efficiency. We also introduced business validation mechanisms and rules for flagging suspicious values (e.g., discrepancies in numbers).
Data quality was our priority – we focused on ensuring high processing accuracy and implementing strategies for data quality improvement at every stage. Data analysis became a key element of the process, enabling continuous solution improvement and better understanding of user needs.
Results: 30,000 documents in two weeks and 2,000 hours of manual work recovered
In the final processing, we achieved:
- processing nearly 30,000 documents in less than two weeks,
- extraction effectiveness at 95% for critical data,
- data ready for reporting and ERP integration,
- recovered approximately 2,000 manual work hours.
Additionally, implementing document processing automation allowed analyzing data with higher accuracy, detecting irregularities, and accelerating business processes.
But what turned out to be most important happened on the interpretation side of results. Thanks to well-processed and organized data, the client gained insights previously unknown. Unrecognized discrepancies, duplicate liabilities, and unnecessary costs were identified.
Result? Real business decisions that brought several million PLN in savings over a year. This shows that the greatest value of GenAI implementation lies not only in speed but in the ability to understand what was hidden in PDF files until now. For clients, this means not only improved customer service and high-quality services but also better understanding of their needs and more effective management of business processes..
What can you do in your document management?
If you face a similar problem of unstructured data:
- Start with an audit: what documents do you have, how many, in what form, what do you expect from them? Already at this stage, it is worth developing a document processing automation implementation strategy to effectively plan the next steps.
- Select key document types and define the required data for extraction. Consider using cloud-based tools that enable integration with other systems and flexible scaling of processes.
- Build a PoC on a small sample: check what works and what doesn’t, using custom models tailored to a specific document structure. This way, there is no need to engage in complex implementation processes, and integration with existing systems runs smoothly.
- Iterate prompt engineering + validation + quality assessment.
- Then scale up.
Remember: AI will not replace humans, but if it does it 10x faster and 10x cheaper – and you gain access to information you previously couldn’t see, which can bring value many times greater than time and resource savings if used properly. Often, it is precisely this data that decides about changing decisions, renegotiations, optimizations – and real money. You have a real reason to use it.

Want to talk about how AI can help your documents?
At Alterdata, we combine data, AI tools, and real business needs. With results – schedule a free consultation!