
























Wszystkie firmowe dane dostępne w jednym miejscu
Integracja danych z różnych źródeł zapewnia lepszą ich lepszą jakość, eliminuje pracę manualną i podnosi jakość analityki.
Porozmawiajmy
Zaufali nam:











Korzyści z integracji danych w jednym miejscu
Spójne dane to lepsza współpraca w organizacji i podstawa trafnych decyzji biznesowych. Dziesiątki systemów, aplikacji, baz danych i setki tysięcy plików – w tym łatwo się pogubić! Integracja źródeł to łączenie wszystkich danych w centralnym miejscu. Zwiększa ona elastyczność firmy i szybkość reakcji na potrzeby biznesowe.

Brak silosów danych
Integracja źródeł usuwa bariery między działami w firmie. Spójne dane są łatwo dostępne dla zespołów, co przyspiesza pracę, zmniejsza ryzyko błędów i wspiera podejmowanie lepszych decyzji.
Szybki dostęp do danych
Automatyzacja pobierania danych ze źródeł eliminuje pracę ręczną, zmniejsza koszty i ryzyko błędów ludzkich. Dane przechowywane w jednym miejscu to także szybsza analityka i raportowanie.
Lepsza integracja z systemami
Połączenie danych w jednym miejscu zapewnia lepszą jakość informacji nie tylko dla ludzi, ale też firmowych systemów, których wydajność zależy w znaczniej mierze od łatwości dostępu do danych.
Wyższa jakość danych
Spójne formaty, brak duplikatów, czy nieprawdziwych danych to większa precyzja pracy. To też możliwości użycia danych do usprawniania biznesu, np. personalizacji doświadczeń klientów.
Szybsze i dokładniejsze wnioski
Integracja źródeł i formatów danych przyspiesza analizy oraz zwiększa precyzję wniosków. Wspiera identyfikację zagrożeń i szans oraz wskazuje obszary do poprawy, np. w obsłudze klienta.
Krótszy time-to-market
Przyspieszenie procesów biznesowych dzięki lepszemu dostępowi do danych to najlepsza metoda na to, by dostarczyć grupie docelowej produkt, czy usługę zanim zrobi to konkurencja.
Zintegruj dane i zwiększ wydajność firmy
PorozmawiajmyNasza filozofia integracji źródeł danych
Integracja danych to nie jednorazowe działanie, ale proces,
który ewoluuje wraz z rozwojem firmy.
Naszym celem jest też edukowanie klientów na temat znaczenia integracji i jej dobrych praktyk, które dają wymierne korzyści:
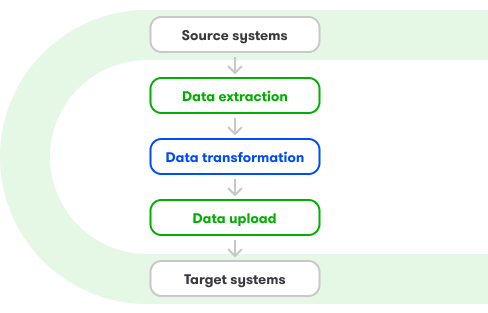
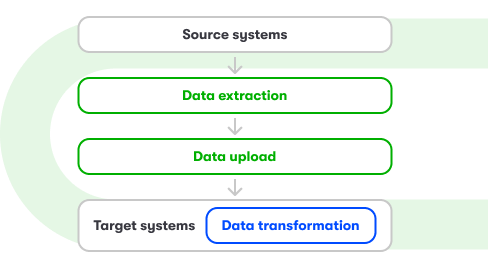
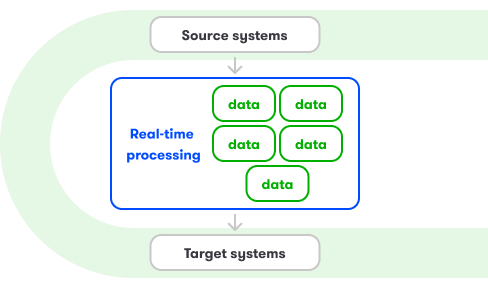
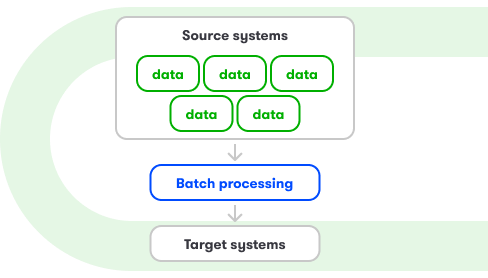
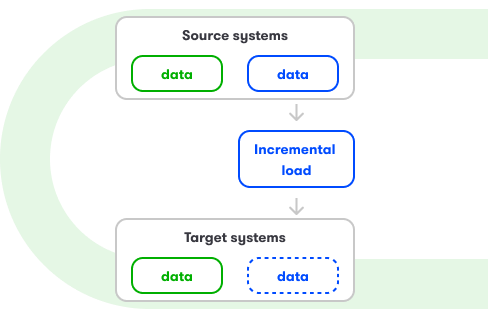
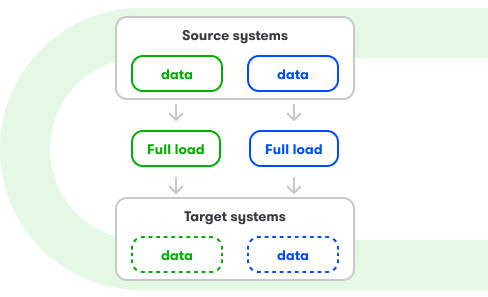
- metody dopasowanej do specyfiki źródeł (np. baz danych, API, systemów firmowych): batch, stream, full load, increment, etc.
- wyboru strategii ELT lub ETL do integracji danych,
- użycia rozwiązań gotowych lub przygotowywanych dla konkretnego klienta oraz wyboru optymalnych narzędzi.
Integracja danych to pierwszy krok na drodze do zbudowania zaufania do danych i podejmowania trafnych decyzji, które wspierają krótkoterminowe sukcesy i długofalowy rozwój.

Historie sukcesu – jak integracja danych zmieniła firmy naszych klientów

Pomogliśmy Celsium zbudować hurtownię danych, która zredukowała koszty o 180 000 zł rocznie
Zintegrowaliśmy dane z liczników, SCADA, systemów billingowych i pogodowych w jednej hurtowni na Google Cloud Platform. Stworzyliśmy zaawansowane procesy ETL, mechanizmy kontroli jakości danych i dashboardy w Tableau, wspierające codzienną analizę produkcji i zużycia ciepła.
Efekt? Wykrywanie awarii liczników w 1 dzień (wcześniej miesiąc), 3× dziennie aktualizowane dane operacyjne i znaczne oszczędności dzięki optymalizacji źródeł ciepła i lepszemu bilansowaniu popytu.

Zbudowaliśmy nowoczesną hurtownię danych w GCP dla Polskiego Światłowodu Otwartego
Pomogliśmy PŚO zaprojektować i wdrożyć skalowalną architekturę Data Lake na Google Cloud Platform. Zintegrowaliśmy 13 źródeł danych, stworzyliśmy automatyczne procesy ELT, zabezpieczenia dostępu i model danych będący jednym źródłem prawdy w organizacji.
Efekt? Niezależność w raportowaniu, szybka integracja nowych systemów, gotowość na przyszłe potrzeby i oszczędność kosztów dzięki eliminacji infrastruktury on-premise.

Pomogliśmy AMS wykorzystać dane z nośników DOOH i utrzymać pozycję lidera reklamy zewnętrznej
Zbudowaliśmy nowoczesny ekosystem danych dla AMS – lidera reklamy OOH i DOOH. Połączyliśmy dane z nośników, systemów wewnętrznych, Proxi.cloud i CitiesAI, tworząc jednolitą hurtownię danych w BigQuery z analizą w czasie zbliżonym do rzeczywistego.
Efekt? Targetowanie oparte na danych, automatyzacja kampanii, lepsze wyniki dla klientów i umocnienie pozycji rynkowej dzięki programmatic buying w oparciu o rzeczywisty zasięg.

Pomogliśmy Tutlo zautomatyzować integrację danych i zbudować nowoczesne ETL w czasie rzeczywistym
We współpracy z zespołem Tutlo zaprojektowaliśmy i wdrożyliśmy architekturę integracji danych opartą o bezserwerowe komponenty Google Cloud. System umożliwia synchronizację danych z dziesiątek źródeł – w tym CRM – z pełnym monitoringiem, automatyzacją CI/CD i gotowością do dalszej skalowalności.
Efekt? Stabilny i elastyczny ekosystem danych, gotowy na automatyzację procesów, projekty ML i dynamiczny rozwój platformy edukacyjnej.

Pomogliśmy FunCraft prognozować ROI i optymalizować budżety UA w branży mobile gaming
Dla amerykańskiego studia gier wdrożyliśmy kompleksowe rozwiązanie BI, integrując dane z Adjust, sklepów i platform reklamowych do hurtowni BigQuery. Zbudowaliśmy zaawansowane dashboardy w Looker Studio oraz modele predykcyjne ROI, które umożliwiają podejmowanie trafnych decyzji budżetowych – nawet przy długim cyklu zwrotu z inwestycji.
Efekt? Zespół marketingu FunCraft działa szybciej, skuteczniej i z pełną kontrolą nad danymi.
Lepsze dane to lepsze decyzje biznesowe
4 problemy w firmie, które łatwo rozwiążesz dzięki integracji źródeł:

Złe dane i brak integracji
Brak jednolitej struktury danych, ich niska jakość i błędy integracji prowadzą do złych wniosków z analiz.
Praca ręczna zmniejsza efektywność
Manualne łączenie danych z różnych źródeł jest czasochłonne, nieefektywne i obciążone ryzykiem błędów ludzkich.
Utrudniony dostęp do informacji
Brak centralizacji danych to ich ręczne pobieranie, a w efekcie wiele źródeł prawdy i brak zaufania do danych.
Niepotrzebne wydatki
Bez integracji nie możesz zrezygnować z części systemów, które w przypadku optymalizacji są całkowicie zbędne.
Metody integracji źródeł danych

Twoje dane kryją w sobie potencjał. Zapytaj nas, jak go wykorzystać
Dlaczego Alterdata?
Łączymy doświadczenie ekspertów, szeroką znajomość technologii i elastyczne podejście do współpracy, aby tworzyć rozwiązania danych realnie dopasowane do potrzeb Twojej organizacji.
Kompleksowa realizacja End-to-End
Prowadzimy cały proces: od doradztwa i wyboru technologii, przez budowę hurtowni danych, po rozwój, utrzymanie i optymalizację rozwiązań. Dzięki temu klient otrzymuje spójne wsparcie na każdym etapie pracy z danymi, bez konieczności koordynowania wielu niezależnych dostawców.
Ekspercki zespół danych
Łączymy kompetencje inżynierów danych, analityków, data scientistów, architektów IT i konsultantów biznesowych, aby odpowiadać zarówno na potrzeby technologiczne, jak i biznesowe. Nasz zespół pomaga przełożyć cele organizacji na konkretne rozwiązania, które realnie wspierają decyzje i rozwój firmy.
Neutralność technologiczna
Dobieramy narzędzia do celu, a nie odwrotnie. Pracujemy z popularnymi technologiami chmurowymi i analitycznymi, m.in. Google Cloud, Azure, AWS, Snowflake, Databricks, Power BI, Tableau czy Looker. Dzięki szerokiej znajomości narzędzi rekomendujemy rozwiązania najlepiej dopasowane do sytuacji klienta, zamiast forsować jedną technologię.
Elastyczny model współpracy
Oferujemy wsparcie dokładnie wtedy, gdy go potrzebujesz, od pojedynczych specjalistów po model Data Team as a Service, bez konieczności budowania pełnego zespołu wewnętrznie. Pozwala to szybko zwiększać kompetencje organizacji i korzystać z wiedzy ekspertów w zakresie dopasowanym do aktualnych potrzeb.
Rozwiązania dopasowane do biznesu
Projektujemy usługi i architekturę pod konkretne wymagania, budżet, branżę, wielkość firmy oraz cele biznesowe klienta. Każde wdrożenie traktujemy indywidualnie, aby technologia wspierała procesy, sposób pracy i priorytety danej organizacji.
Bezpieczna architektura
Tworzymy skalowalne, bezpieczne rozwiązania gotowe na rozwój organizacji, rosnącą ilość danych i migrację do nowoczesnych środowisk chmurowych. Dbamy o kontrolę dostępu, stabilność i możliwość dalszej rozbudowy, aby platforma danych mogła rozwijać się razem z firmą.
Tech stack: fundament naszej pracy
Poznaj narzędzia i technologie, które napędzają rozwiązania tworzone przez Alterdata.

Google Cloud Storage umożliwia przechowywania danych w chmurze i wydajność, elastyczne zarządzanie dużymi zbiorami danych. Zapewnia łatwy dostęp do danych i wsparcie zaawansowanych analiz.

Azure Data Lake Storage to usługa przechowywania oraz analizowania danych ustrukturyzowanych i nieustrukturyzowanych w chmurze, stworzona przez Microsoft. Data Lake Storage jest skalowalne i obsługuje różne formaty danych.

Amazon S3 to usługa chmurowa do bezpiecznego przechowywania danych o praktycznie nieograniczonej skalowalności. Jest wydajna i zapewnia spójność oraz łatwy dostępu do danych.

Databricks to chmurowa platforma analityczna, łącząca inżynierię i analizę danych oraz machine learning i modele predykcyjne. Z wysoką wydajnością przetwarza ona także duże zbiory danych.

Microsoft Fabric to zintegrowane środowisko analityczne, łączące w różne narzędzia, takie jak Power BI, Data Factory, czy Synapse. Platforma obsługuje cały cyklu życia danych, integrację, przetwarzanie, analizę i wizualizację wyników.
Google Big Lake to usługa, która łączy w sobie cechy hurtowni oraz jezior danych i ułatwia zarządzanie danymi w różnych formatach oraz lokalizacjach. Pozwala także przetwarzać duże zbiory danych bez przenoszenia między systemami.

Google Cloud Dataflow do usługa przetwarzania dużych ilości danych oparta na Apache Beam. Wspiera rozproszone przetwarzanie danych w czasie rzeczywistym oraz zaawansowane analizy

Azure Data Factory to usługa integracji danych w chmurze, która automatyzuje przepływy danych i orkiestruje procesy przetwarzania. Umożliwia łączenie danych ze źródeł chmurowych i lokalnych do przetwarzania w jednym środowisku.

Apache Kafka przetwarza w czasie rzeczywistym strumienie danych i wspiera zarządzanie dużymi ilościami danych z różnych źródeł. Pozwala analizować zdarzenia natychmiast po ich wystąpieniu.
Pub/Sub służy do przesyłania wiadomości między aplikacjami, przetwarzania strumieni danych w czasie rzeczywistym, ich analizy i tworzenia kolejek komunikatów. Dobrze integruje się z mikrousługami oraz architekturami sterowanymi zdarzeniami (EDA).
Google Cloud Run obsługuje aplikacje kontenerowe w skalowalny i zautomatyzowany sposób, przez co optymalizuje koszty oraz zasoby. Pozwala na elastyczne i wydajne zarządzanie aplikacjami w chmurze, zmniejszając obciążenie pracą.

Azure Functionsto inne rozwiązanie bezserwerowe, które uruchamia kod w reakcji na zdarzenia, eliminując potrzebę zarządzania serwerami. Jego inne zalety to możliwość automatyzowania procesów oraz integrowania różnych usług.

AWS Lambda to sterowana zdarzeniami, bezserwerowa funkcja jako usługa (FaaS), która umożliwia automatyczne uruchamianie kodu w odpowiedzi na zdarzenia. Pozwala uruchamiać aplikacje bez infrastruktury serwerowej.

Azure App Service to platforma chmurowa, służąca do uruchamiania aplikacji webowych i mobilnych. Oferuje automatyczne skalowanie zasobów i integrację z narzędziami DevOps, (np. GitHub, Azure DevOps)

Snowflake to platforma, która umożliwia przechowywanie, przetwarzanie i analizowanie dużych zbiorów danych w chmurze. Jest łatwo skalowalna, wydajna, zapewnia też spójność oraz łatwy dostępu do danych.

Amazon Redshift to hurtownia danych w chmurze, która umożliwia szybkie przetwarzanie i analizowanie dużych zbiorów danych. Redshift oferuje także tworzenie złożonych analiz i raportów z danych w czasie rzeczywistym.
BigQuery to skalowalna platforma analizy danych od Google Cloud. Umożliwia ona szybkie przetwarzanie dużych zbiorów danych, analitykę oraz zaawansowane raportowanie. Ułatwia dostęp do danych dzięki integracji z różnymi ich źródłami.

Azure Synapse Analytics to platforma łącząca hurtownię danych, przetwarzanie big data oraz analitykę w czasie rzeczywistym. Umożliwia przeprowadzanie skomplikowanych analiz na dużych wolumenach danych.

Data Build Tool umożliwia łatwą transformację i modelowanie danych bezpośrednio w bazach danych. Pozwala tworzyć złożone struktury, automatyzować procesy i zarządzać modelami danych w SQL.

Dataform jest częścią Google Cloud, która automatyzuje transformację danych w BigQuery, w oparciu o język zapytań SQL. Wspiera bezserwerową orkiestrację strumieni danych i umożliwia pracę zespołową z danymi.
Pandas to biblioteka struktur danych oraz narzędzi analitycznych w języku Python. Jest przydatna w manipulowaniu danymi i analizach. Pandas jest używana szczególnie w statystyce i machine learningu.

PySpark to interfejs API dla Apache Spark, który pozwala przetwarzać duże ilości danych w rozproszonym środowisku, w czasie rzeczywistym. To narzędzie jest proste w użyciu oraz wszechstronne w działaniu.

Looker Studio to narzędzie służące do eksploracji i zaawansowanej wizualizacji danych pochodzących z różnych źródeł, w formie czytelnych raportów, wykresów i dashboardów. Ułatwia współdzielenie danych oraz wspiera równoczesną pracę wielu osób, bez potrzeby kodowania.

Tableau, aplikacja od Salesforce, to wszechstronne narzędzie do analiz i wizualizacji danych, idealne dla osób szukających intuicyjnych rozwiązań. Cenione za wizualizacje danych przestrzennych i geograficznych, szybkie identyfikowanie trendów oraz dokładność analiz danych.
Power BI, platforma Business Intelligence koncernu Microsoft, wydajnie przekształca duże ilości danych w czytelne, interaktywne wizualizacje i przystępne raporty. Łatwo integruje się z różnymi źródłami danych oraz monitoruje KPI w czasie rzeczywistym.
Looker to platforma chmurowa do Business Intelligence oraz analityki danych, która pozwala eksplorować, udostępniać oraz wizualizować dane i wspiera procesy decyzyjne. Looker wykorzystuje też uczenie maszynowe do automatyzacji procesów i tworzenia predykcji.
Terraform to narzędzie open-source, które pozwala na zarządzanie infrastrukturą jako kodem oraz automatyczne tworzenie i aktualizację zasobów w chmurze. Wspiera efektywne kontrolowanie infrastruktury, minimalizuje ryzyko błędów, zapewnia transparentność i powtarzalność procesów.

GCP Workflows automatyzuje przepływy pracy w chmurze, a także ułatwia zarządzanie procesami łączącymi usługi Google Cloud. To narzędzie pozwala oszczędzać czas dzięki unikaniu dublowania działań, poprawia jakości pracy, eliminując błędy, oraz umożliwia wydajne zarządzanie zasobami.

Apache Airflow zarządza przepływem pracy, umożliwia planowanie, monitorowanie oraz automatyzację procesów ETL i innych zadań analitycznych. Daje też dostęp do statusu zadań ukończonych i bieżących oraz wgląd w logi ich wykonywania.

Rundeck to narzędzie open-source do automatyzacji, które umożliwia planowanie, zarządzanie oraz uruchamianie zadań na serwerach. Pozwala na szybkie reagowanie na zdarzenia i wspiera optymalizację zadań administracyjnych.

Python to kluczowy język programowania w uczeniu maszynowym (ML). Dostarcza bogaty ekosystem bibliotek, takich jak TensorFlow i scikit-learn, umożliwiając tworzenie i testowanie zaawansowanych modeli.

BigQuery ML pozwala na budowę modeli uczenia maszynowego bezpośrednio w hurtowni danych Google wyłącznie za pomocą SQL. Zapewnia szybki time-to-market, jest efektywny kosztowo, umożliwia też szybką pracę iteracyjną.

R to język programowania do obliczeń statystycznych i wizualizacji danych, do tworzenia oraz testowania modeli uczenia maszynowego. Umożliwia szybkie prototypowanie oraz wdrażanie modeli ML.

Vertex AI służy do deplymentu, testowania i zarządzania gotowymi modeli ML. Zawiera także gotowe modele przygotowane i trenowane przez Google, np. Gemini. Vertex AI wspiera też niestandardowe modele TensorFlow, PyTorch i inne popularne frameworki.
FAQ
Ile czasu zajmuje integracja źródeł danych?
Czas potrzebny na integrację danych zależy od stopnia złożoności projektu i liczby źródeł danych firmowych, a także wyboru użycia rozwiązań gotowych lub tworzonych specjalnie dla klienta. Efekty w postaci szybszego dostępu do danych i większego zaufania do nich są zwykle widoczne już po kilku tygodniach od rozpoczęcia prac.
Po czym poznam, że efekt integracji źródeł jest pozytywny, jakie ustalić KPI?
Kluczowymi KPI będą tu zwiększenie niezawodności procesów ETL/ELT, redukcja liczby błędów w raportach oraz poprawa wydajności operacji wykorzystujących zintegrowane dane. Wspólnie dobierzemy wskaźniki specyficzne dla Twojej firmy, byś mógł monitorować, jak integracja danych przekłada się na podejmowanie bardziej trafnych decyzji.
Czy integracja źródeł danych to rozwiązanie tylko dla dużych firm?
Nie, każda organizacja, która wykorzystuje dane ze swoich systemów, powinna zadbać o ich jakość. Wprowadzenie jednego źródła prawdy i ułatwienie pracownikom dostępu do danych zwiększa efektywność działania w małych oraz dużych firmach, pozwalając im szybciej podejmować lepsze decyzje biznesowe.
Czy nowe technologie będą kompatybilne z naszą technologią?
Nasze rozwiązania integracyjne są projektowane z myślą o kompatybilności z istniejącymi i przyszłymi technologiami. Dostosowujemy się do Twoich wymagań, zapewniając elastyczność i skalowalność.
Czy do tej usługi muszę mieć jakieś kompetencje w swojej organizacji?
Nie musisz posiadać specjalistycznych kompetencji w swojej organizacji. Nasz zespół ekspertów prowadzi cały proces wdrożenia, zapewniając pełne wsparcie i szkolenia dla Twojego zespołu.
Czy zewnętrzny analityk lub inżynier danych ma dostęp do wszystkich informacji naszej firmy?
Dbamy o pełne bezpieczeństwo danych. Dostęp do informacji jest ściśle kontrolowany, a nasi eksperci mają wgląd wyłącznie do danych niezbędnych do realizacji projektu, zgodnie z najwyższymi standardami ochrony. Nie pobieramy danych, są one przechowywane wyłącznie po stronie klienta.
Co jeśli w przyszłości pojawią się problemy z jakością danych?
Oferujemy stałe wsparcie w monitorowaniu i poprawie jakości danych. W przypadku problemów zapewniamy szybkie i skuteczne rozwiązania, które utrzymują integralność danych.
Czy firma jest obiektywna technologicznie i weźmie pod uwagę nasze preferencje technologii?
Alterdata jest niezależna technologicznie. Nasze rekomendacje zawsze opierają się na Twoich preferencjach oraz na najlepszych rozwiązaniach dostępnych na rynku, gwarantując optymalną skuteczność i zgodność z Twoimi wymaganiami. Jesteśmy partnerem wielu dostawców technologii, ale ich nie sprzedajemy. To daje nam maksymalną obiektywność przy wyborze najlepiej pasującej technologii do rozwiązania Twojego problemu.